Auto Insurance Claims Platform: GLM Pricing, IBNR Reserves, and Fraud Detection in One Dashboard
R Shiny dashboard with 140,000 synthetic policies calibrated to the Mexican market. Two-part GLM pricing engine, IBNR reserves via Chain Ladder and Bornhuetter-Ferguson, Monte Carlo stress testing with VaR/TVaR, and Mahalanobis-based fraud detection. 17 modules, bslib architecture, deployed on Cloud Run.
In Mexico, roughly 70% of vehicles circulate without insurance. For the insurers covering the remaining 30%, the central question is always the same: how much to charge, how much to reserve, and where the risk lies. This project builds a complete actuarial platform to answer those three questions using synthetic data calibrated to real Mexican market parameters.
The data: 140,000 policies over five years
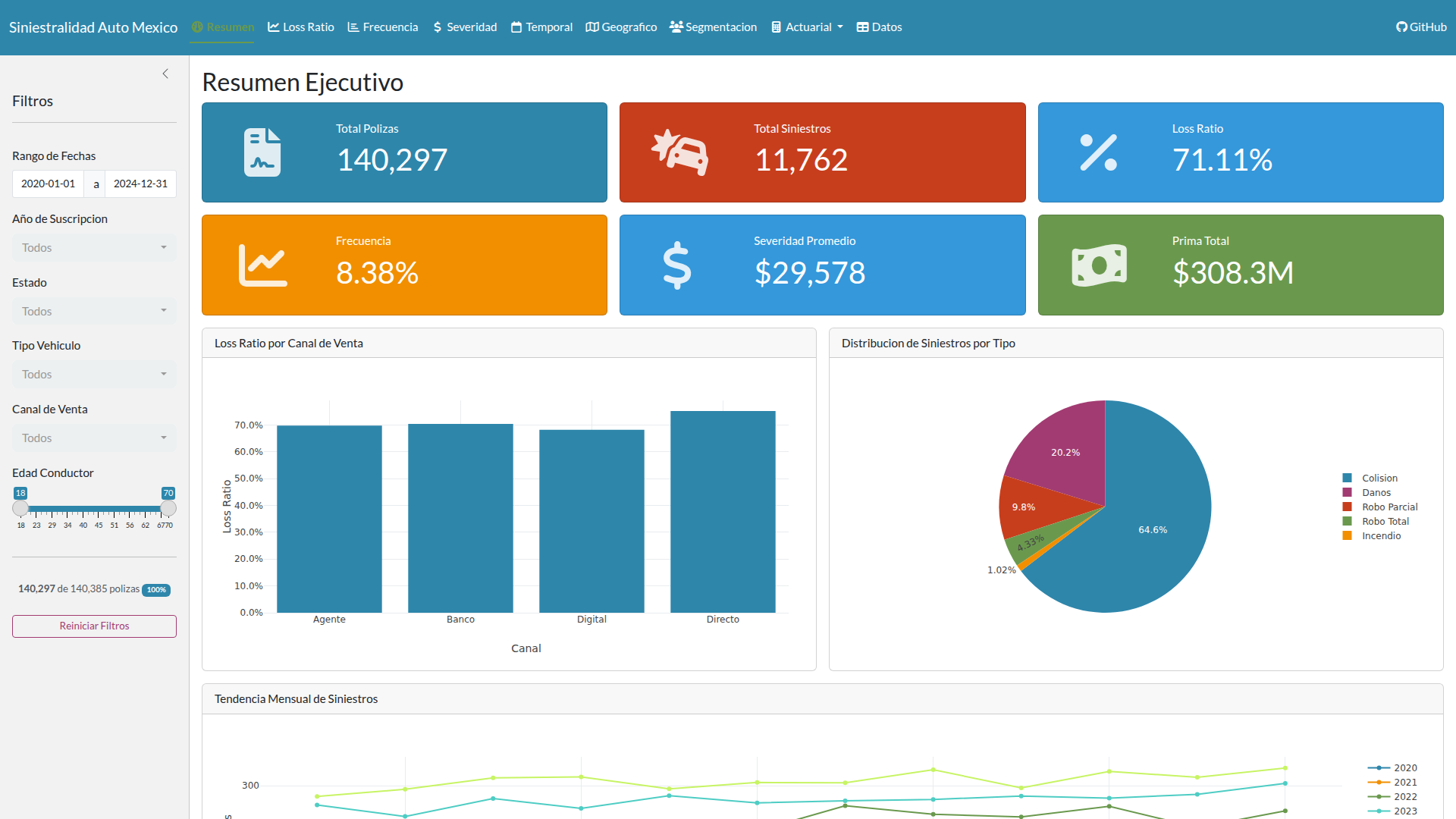
The dataset covers the 2020-2024 period with 140,385 policies, 11,762 claims, and 24,900 development payments distributed across five development years (0-4). The generation starts with 12,000 new policies per year with an 82% renewal rate, producing the organic growth a real portfolio would show.
Calibration parameters come from public sources: 8.5% base frequency (CONDUSEF), $24,000 MXN average severity (AMIS), 75% target loss ratio (AMIS sector average). The claims distribution follows the typical Mexican auto pattern: collision 65%, damage 20%, partial theft 10%, total theft 4%, fire 1%. The development pattern uses the short tail characteristic of auto: 60% paid in the accident year, 85% at first development, 95% at second, 99% at third, 100% at fourth.
The portfolio covers 13 Mexican states, 18 models from 10 brands (Nissan, Volkswagen, Chevrolet, Toyota, Ford, Honda, Hyundai, Mazda, Kia, Seat), and three vehicle types. The achieved KPIs are consistent with the market: 71.1% loss ratio (target 75%), 8.38% frequency (target 8.5%), $29,396 severity (target $24,000; the deviation reflects 4% annual inflation compounded over five years).
GLM pricing engine
Auto insurance pricing breaks into two fundamental questions: how often do claims happen, and when they do, how much do they cost? This split is the industry standard because frequency and severity respond to different risk factors and need different probability distributions.
The first question uses a Poisson GLM with log link. The response is the claim count per policy, with exposure as an offset to account for policies active only part of the year. The second uses a Gamma GLM, also with log link, applied to individual claim amounts. This two-part architecture has been the de facto standard in actuarial modeling for decades because it aligns with how claims actually behave in practice.
The predictors capture the usual suspects: driver age (four brackets: under 25, 25-35, 35-50, 50+), gender, vehicle type, geographic risk zone (high, medium, low), sales channel, and credit score segment. What surprised me most was how much geographic zone dominates. Drivers under 25 trigger a 1.35x surcharge, SUVs warrant 1.15x, but high-risk zones like CDMX and Estado de Mexico hit 1.30x. Zone matters as much as age, and both matter more than vehicle type in this dataset.
The interactive quoter calculates the pure premium in real time from any insured’s profile. You can inspect the relativity tables by risk factor, watch the waterfall premium decomposition show how each factor accumulates, and review model diagnostics: residual plots, Q-Q plots, and observed versus predicted frequencies stratified by each factor.
IBNR reserves
Reserves require two methodologies working in parallel: Chain Ladder and Bornhuetter-Ferguson. Chain Ladder calculates volume-weighted link ratios, which then feed into cumulative development factors (CDFs) to ultimate, complete with Mack standard error for stability diagnostics. The IBNR itself is just the difference between projected ultimate and what you’ve actually paid.
Bornhuetter-Ferguson offers a different angle. Instead of trusting the data to tell you where development is headed, it blends the Chain Ladder projection with an a priori loss ratio expectation (75% by default, adjustable between 60% and 90%). This method shines for immature accident years, where early link ratios can be erratic because the sample is small and every single claim moves the needle.
The interface renders the full development triangle in both incremental and cumulative views, alongside the link ratios table and CDFs. You can compare the IBNR estimates side by side across accident years to see where the two methods diverge most. This connects directly to SIMA, which handles life insurance reserves. Both SIMA and this platform use the same Chain Ladder and Bornhuetter-Ferguson mechanics, but the resemblance ends there. Auto claims develop over four years; life claims extend for decades. The tail lengths are incommensurable.
Monte Carlo stress testing
The scenario module builds a collective risk model: aggregate frequency comes from a Poisson distribution, individual claim costs from a Gamma. The simulation then generates thousands of possible futures (1,000 to 50,000 realizations), each time drawing a different aggregate loss outcome. You can stress-test the portfolio by scaling frequency up or down (0.5x to 2.0x, representing milder or harsher accident environments) and severity independently (same 0.5x to 2.0x range, for inflation or claims inflation shocks).
Every run computes VaR at 95%, 99%, and 99.5% confidence levels, along with TVaR (the average of losses beyond each threshold), mean, and standard deviation. Visualizations layer the baseline loss density against the stressed scenario side by side, with an exceedance curve showing the cumulative tail and an impact table quantifying the change in each risk metric. TVaR matters most here for regulatory compliance. The CNSF requires it for solvency capital requirement (RCS) calculations, so this dashboard explicitly uses it, not VaR, as the primary risk measure.
Fraud detection
Fraud gets flagged through two parallel channels that feed into a single score. The first is statistical: Mahalanobis distance. For each claim type separately, the model looks at three key variables: the claim amount itself, how long the policyholder waited before reporting (in days), and the deductible. It computes the multivariate distance from each claim to the “normal” region defined by the full sample. That distance becomes a percentile for easier interpretation (0 = typical, 100 = extreme). A regularized covariance matrix prevents the math from blowing up on singular cases.
The second channel is rule-based. Five heuristics flag structural red flags: multiple claims on the same policy within 60 days, a claim filed within 30 days of policy inception, an amount exceeding three times the median for that claim type, a report delay longer than 10 days, or an amount above 90% of the sum insured. Each rule votes independently.
The final composite score weights 40% to the Mahalanobis statistic and 60% to the heuristic flags. A threshold of 0.7 identifies the claims most likely to warrant investigation.
Engineering decisions
The application contains 17 R modules organized across three layers. The bottom layer holds 4 utility modules (metrics, theme, data, export) that do all the heavy mathematical lifting. The top layer contains 13 interface modules, one per dashboard tab. This separation is intentional and strict: the actuarial code has zero Shiny dependencies. You can test the pricing engine or the reserving functions in isolation, in a plain R session, without a web server.
The UI layers on top with bslib and Bootstrap 5 for responsive layout. Plotly handles chart interactivity, DT handles table filtering and sorting. Both libraries integrate cleanly into Shiny and produce output the browser understands natively.
Deployment mirrors the pension simulator and SIMA: Docker container on Google Cloud Run, with GitHub Actions driving CI/CD and Workload Identity Federation handling authentication.
What I learned
The variable that most affects pricing in the Mexican auto market is the geographic zone, outweighing driver age or vehicle type. CDMX and Estado de Mexico accumulate the highest frequency and severity by far. This aligns perfectly with AMIS theft statistics; theft is concentrated in those two states, and the GLMs capture that signal clearly.
The practical difference between Chain Ladder and Bornhuetter-Ferguson surfaces in immature accident years. Chain Ladder rides the volatility of early link ratios up and down; Bornhuetter-Ferguson anchors itself to the a priori loss ratio expectation and smooths the noise. For auto with its short four-year development tail, the divergence is modest. In long-tail liability, the difference would be dramatic.
One critical limitation: the data is entirely synthetic. Variable correlations—say, between geographic zone and vehicle type—are by design, not discovered. A real dataset from AMIS or CONDUSEF would reveal patterns and interactions that don’t exist in generated data. The next step would be obtaining CONDUSEF public datasets or negotiating a data-sharing agreement with an actual insurer to retrain the GLMs on market reality.
The application is deployed on Google Cloud Run and the source code is on GitHub.