Plataforma de Siniestralidad Auto: tres preguntas que toda aseguradora necesita responder
En México, cerca del 70% de los vehículos circulan sin seguro. Para las aseguradoras que cubren el resto, el negocio se reduce a tres preguntas: cuánto cobrar, cuánto reservar y dónde está el fraude. Esta plataforma construye un dashboard que responde las tres con datos calibrados al mercado mexicano, separando frecuencia de severidad para tarificar, estimando lo que falta por pagar con dos métodos que se complementan, y detectando reclamaciones anómalas antes de que lleguen a ajuste.
En México, cerca del 70% de los vehículos circulan sin seguro. Para las aseguradoras que cubren el 30% restante, el negocio se reduce a tres preguntas: cuánto cobrar por cada póliza, cuánto reservar para siniestros que todavía no se reportan, y cuáles reclamaciones merecen investigación antes de pagarse. Este proyecto construye un dashboard que responde las tres.
Los datos
La cartera es sintética, pero los parámetros vienen de fuentes reales. La frecuencia de siniestros, la severidad promedio y el loss ratio objetivo están calibrados con datos públicos de la CONDUSEF y la AMIS. La distribución de tipos de siniestro sigue el patrón típico de autos en México: colisión como evento dominante, seguido de daños, robo parcial, robo total e incendio como cola. El patrón de desarrollo usa la cola corta característica de autos, donde la mayor parte de los pagos se concentra en el año de ocurrencia.
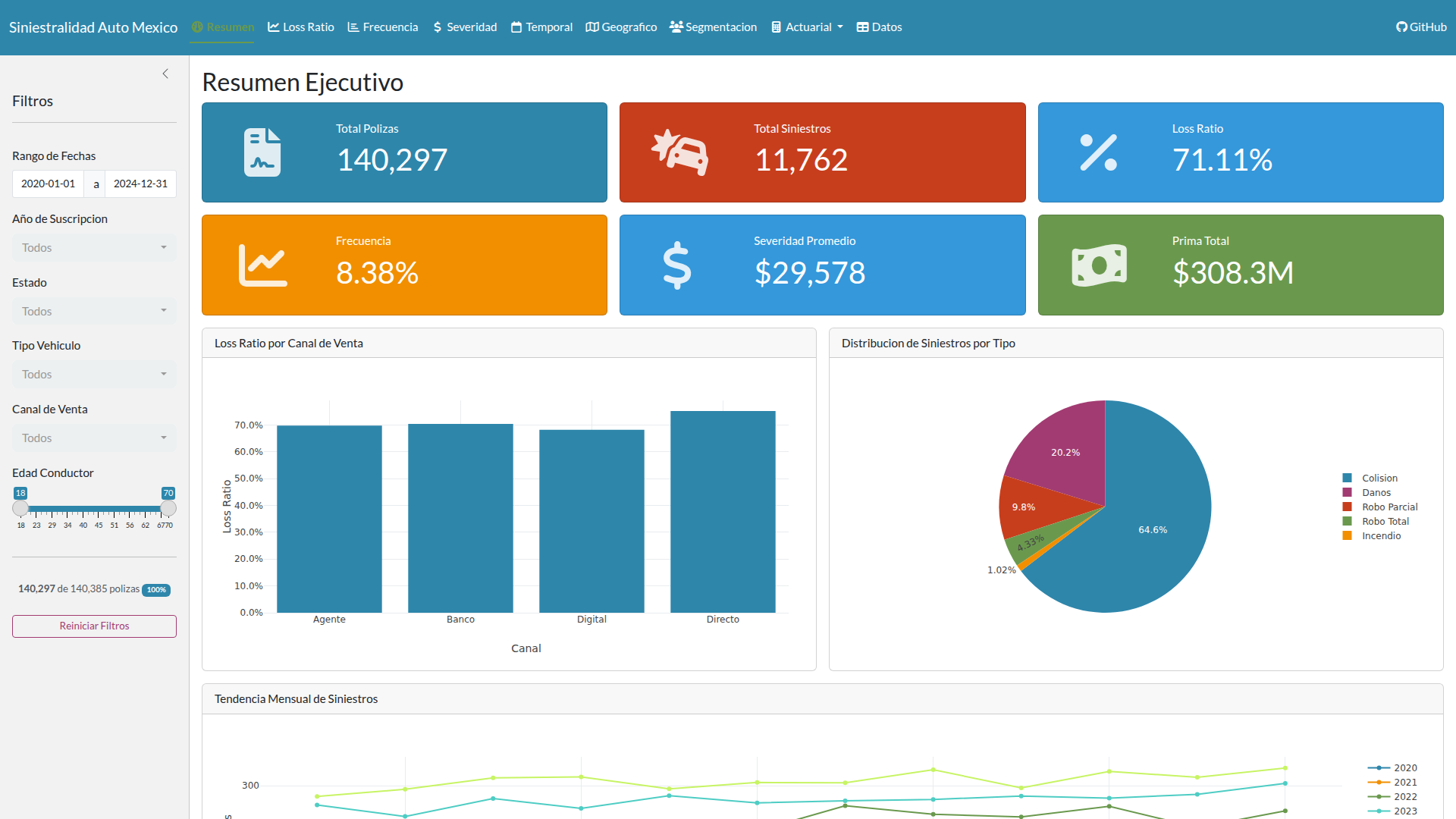
Los KPIs que produce la cartera son coherentes con el mercado: el loss ratio queda cerca del objetivo sectorial, y la desviación en severidad refleja la inflación acumulada sobre el período de simulación. Si los parámetros fueran inventados, esos indicadores no cuadrarían.
La cartera cubre varios estados mexicanos, múltiples marcas y modelos, y tres tipos de vehículo. Lo que importa aquí es que la diversidad geográfica y vehicular permite que el modelo de tarificación capture señales reales de riesgo.
Tarificación: separar frecuencia de severidad
En seguros de autos, un conductor que choca frecuentemente y uno que tiene un solo siniestro caro representan riesgos distintos. El modelo de tarificación separa estas dos dimensiones porque responden a factores diferentes: la frecuencia depende de hábitos de conducción y zona geográfica; la severidad depende del valor del vehículo y del tipo de cobertura.
Lo que más me sorprendió fue el peso de la zona geográfica. Los conductores jóvenes generan un recargo importante, los SUVs otro, pero zonas de alto riesgo como CDMX y Estado de México alcanzan un recargo comparable al de la edad. La zona importa tanto como la edad del conductor, y ambas importan más que el tipo de vehículo. Esto se alinea con las estadísticas de robo de la AMIS: el robo se concentra en esos dos estados, y el modelo captura esa señal claramente.
El cotizador interactivo calcula la prima en tiempo real a partir del perfil de cualquier asegurado. Puedes inspeccionar cómo cada factor de riesgo (edad, zona, vehículo, canal) se acumula en el precio final a través de una descomposición waterfall.
Reservas: estimar lo que falta por pagar
Los siniestros de autos tienen una particularidad útil: se desarrollan rápido. La mayor parte de los pagos ocurre en el año del accidente, y al cuarto año ya está todo liquidado. Esa cola corta permite estimar con razonable confianza cuánto falta por pagar de siniestros que ya ocurrieron pero aún no se reportaron.
La plataforma usa dos métodos en paralelo. El primero proyecta a partir de cómo se han desarrollado históricamente los pagos: si los años anteriores muestran que al primer desarrollo ya se pagó el 85%, ese patrón se aplica a los años más recientes. El segundo mezcla esa proyección con una expectativa previa del loss ratio, lo que lo hace más estable en años recientes donde los datos son escasos y cada siniestro individual mueve mucho el resultado.
La interfaz muestra el triángulo de desarrollo completo y permite comparar las estimaciones de ambos métodos lado a lado por año de accidente. Donde más divergen es exactamente donde más valor aporta tener los dos: en los años inmaduros.
Esto conecta con SIMA, que maneja reservas de seguros de vida. Ambas plataformas usan la misma mecánica de estimación, pero el parecido termina ahí. Los siniestros de autos se desarrollan en cuatro años; los de vida se extienden décadas. Las colas son incomparables.
Pruebas de estrés: qué pasa si el mundo empeora
El módulo de escenarios simula miles de futuros posibles para la cartera, variando la frecuencia de siniestros (qué pasa si hay más accidentes) y la severidad (qué pasa si los siniestros cuestan más, por ejemplo por inflación). Cada corrida produce una distribución de pérdidas que permite responder preguntas como: con el 99.5% de confianza, cuál es la peor pérdida esperada.
La CNSF requiere una medida específica de riesgo de cola para los cálculos de capital de solvencia (RCS): el promedio de pérdidas que superan un umbral dado. El dashboard la usa como medida primaria porque es lo que un actuario necesita reportar.
Las visualizaciones superponen la distribución de pérdidas del escenario base contra el estresado, con una curva de excedencia mostrando la cola acumulada. El valor está en poder mover los parámetros y ver en tiempo real cómo cambia el perfil de riesgo de la cartera.
Detección de fraude: identificar lo anómalo
El fraude se detecta por dos vías que se combinan en un solo score. La primera es estadística: para cada tipo de siniestro, el modelo mide qué tan lejos está cada reclamación del comportamiento típico de la cartera, considerando el monto, el tiempo de reporte y el deducible. Una reclamación que se aleja mucho del patrón normal en varias dimensiones simultáneamente merece atención.
La segunda vía es por reglas de negocio: múltiples siniestros en la misma póliza en poco tiempo, siniestros reportados justo después de contratar la póliza, montos muy por encima de la mediana para ese tipo de siniestro, retrasos inusuales en el reporte, o montos cercanos a la suma asegurada. Cada regla vota independientemente.
El score compuesto combina ambas vías. Lo que la distancia estadística captura (patrones sutiles que un ajustador no vería en una tabla) y lo que las reglas capturan (señales estructurales que la experiencia operativa del sector conoce bien) se complementan. Ninguna de las dos es suficiente sola.
Lo que aprendí
La variable que más afecta la tarificación en autos mexicanos es la zona geográfica, por encima de la edad del conductor o el tipo de vehículo. CDMX y Estado de México acumulan la mayor frecuencia y severidad.
La diferencia práctica entre los dos métodos de reservas emerge en años de accidente recientes. El primero amplifica la volatilidad de los datos tempranos; el segundo se ancla a la expectativa previa y suaviza el ruido. Para autos con su cola corta, la divergencia es modesta. En responsabilidad civil de cola larga, la diferencia sería dramática.
Una limitación que hay que nombrar: los datos son completamente sintéticos. Las correlaciones entre variables son por diseño. Un conjunto de datos real de la AMIS o la CONDUSEF revelaría patrones e interacciones que no existen en datos generados. El siguiente paso sería obtener datasets públicos o negociar un acuerdo con una aseguradora real para reentrenar los modelos con datos del mercado.
Repositorio: github.com/GonorAndres/CarteraSeguroAutos
Aplicación en vivo: cartera-autos en Cloud Run