Plataforma de Siniestralidad Auto: Tarificación GLM, Reservas IBNR y Detección de Fraude en un Solo Dashboard
Dashboard R Shiny con 140,000 pólizas sintéticas calibradas al mercado mexicano. Motor de tarificación GLM de dos partes (Poisson frecuencia + Gamma severidad), reservas IBNR por Chain Ladder y Bornhuetter-Ferguson, pruebas de estrés Monte Carlo con VaR/TVaR y detección de fraude por distancia de Mahalanobis. 17 módulos, arquitectura bslib, desplegado en Cloud Run.
En México, cerca del 70% de los vehículos circulan sin seguro. Para las aseguradoras que cubren el 30% restante, la pregunta central es la misma de siempre: cuánto cobrar, cuánto reservar y dónde está el riesgo. Este proyecto construye una plataforma actuarial completa para responder esas tres preguntas con datos sintéticos calibrados a parámetros reales del mercado mexicano.
Los datos: 140,000 pólizas en cinco años
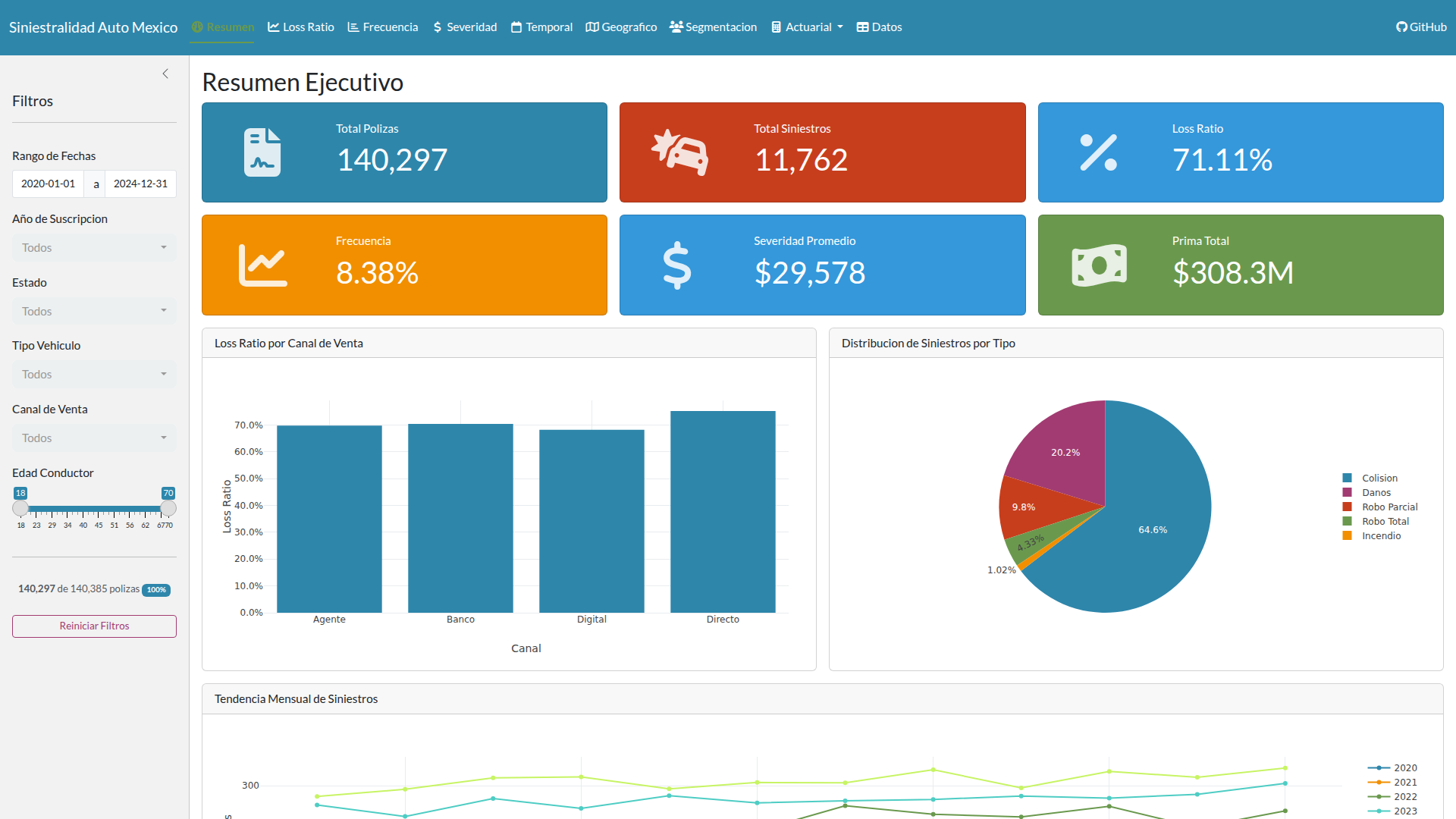
El dataset cubre el período 2020-2024 con 140,385 pólizas, 11,762 siniestros y 24,900 pagos de desarrollo distribuidos en cinco años de desarrollo (0-4). La generación parte de 12,000 pólizas nuevas por año con una tasa de renovación del 82%, produciendo el crecimiento orgánico que vería una cartera real.
Los parámetros de calibración vienen de fuentes públicas: frecuencia base de 8.5% (CONDUSEF), severidad promedio de $24,000 MXN (AMIS), loss ratio objetivo de 75% (promedio sectorial AMIS). La distribución de siniestros sigue el patrón típico de autos en México: colisión 65%, daños 20%, robo parcial 10%, robo total 4%, incendio 1%. El patrón de desarrollo usa la cola corta característica de autos: 60% pagado en el año de ocurrencia, 85% al primer desarrollo, 95% al segundo, 99% al tercero, 100% al cuarto.
La cartera cubre 13 estados mexicanos, 18 modelos de 10 marcas (Nissan, Volkswagen, Chevrolet, Toyota, Ford, Honda, Hyundai, Mazda, Kia, Seat) y tres tipos de vehículo. Los KPIs logrados son coherentes con el mercado: loss ratio de 71.1% (objetivo 75%), frecuencia de 8.38% (objetivo 8.5%), severidad de $29,396 (objetivo $24,000; la desviación refleja la inflación acumulada al 4% anual sobre cinco años).
Motor de tarificación GLM
En seguros de autos, la tarificación responde a dos preguntas fundamentales: con qué frecuencia ocurren los siniestros y cuánto cuestan cuando suceden. Este desglose es el estándar de la industria porque la frecuencia y la severidad responden a factores de riesgo distintos y requieren distribuciones de probabilidad diferentes.
La primera pregunta se contesta con un GLM Poisson y liga log. La variable respuesta es el número de siniestros por póliza, con la exposición como offset para ajustar por pólizas que no permanecen activas todo el año. La segunda usa un GLM Gamma, también con liga log, aplicado a los montos individuales de cada siniestro. Este diseño de dos partes es el estándar de facto en modelado actuarial desde hace décadas porque refleja cómo se comportan realmente los siniestros en la práctica.
Los predictores capturan lo esperado: edad del conductor (menores de 25, 25-35, 35-50, 50+), género, tipo de vehículo, zona geográfica de riesgo (alta, media, baja), canal de venta y segmento de score crediticio. Lo que más me sorprendió fue el peso de la zona geográfica. Los conductores menores de 25 disparan un recargo de 1.35x, los SUVs ameritan 1.15x, pero zonas de alto riesgo como CDMX y Estado de México alcanzan 1.30x. La zona importa tanto como la edad, y ambas importan más que el tipo de vehículo.
El cotizador interactivo calcula la prima pura en tiempo real a partir del perfil de cualquier asegurado. Puedes inspeccionar las tablas de relatividades por cada factor de riesgo, observar cómo la descomposición waterfall muestra cómo cada factor se acumula en el precio final, y revisar los diagnósticos: gráficos de residuales, gráficos Q-Q y frecuencias observadas versus predichas estratificadas por cada factor.
Reservas IBNR
Las reservas requieren dos metodologías que trabajan en paralelo: Chain Ladder y Bornhuetter-Ferguson. Chain Ladder calcula link ratios ponderados por volumen, que luego alimentan los factores de desarrollo acumulados (CDFs) hasta el ultimado, completo con error estándar de Mack para diagnósticos de estabilidad. El IBNR es simplemente la diferencia entre el ultimado proyectado y lo que ya pagaste.
Bornhuetter-Ferguson ofrece una perspectiva distinta. En lugar de confiar en que los datos te digan hacia dónde va el desarrollo, mezcla la proyección de Chain Ladder con una expectativa a priori del loss ratio (75% por defecto, ajustable entre 60% y 90%). Este método brilla en años de accidente inmaduros, donde los primeros link ratios pueden ser erráticos porque la muestra es pequeña y cada siniestro individual mueve la aguja.
La interfaz renderiza el triángulo de desarrollo completo en vistas tanto incremental como acumulada, junto con la tabla de link ratios y los CDFs. Puedes comparar lado a lado las estimaciones de IBNR por año de accidente para ver dónde divergen más los dos métodos. Esto conecta directamente con SIMA, que maneja reservas de seguros de vida. Ambas plataformas usan la misma mecánica de Chain Ladder y Bornhuetter-Ferguson, pero el parecido termina ahí. Los siniestros de autos se desarrollan en cuatro años; los de vida se extienden décadas. Las colas son incomparables.
Pruebas de estrés Monte Carlo
El módulo de escenarios construye un modelo de riesgo colectivo: la frecuencia agregada proviene de una distribución Poisson, los costos individuales de una Gamma. La simulación luego genera miles de futuros posibles (de 1,000 a 50,000 realizaciones), cada vez extrayendo un resultado de pérdida agregada distinto. Puedes someter la cartera a pruebas de estrés escalando la frecuencia hacia arriba o abajo (0.5x a 2.0x, representando ambientes de accidentalidad más leves o severos) y la severidad independientemente (igual rango 0.5x a 2.0x, para shocks de inflación).
Cada corrida calcula VaR al 95%, 99% y 99.5%, junto con TVaR (el promedio de pérdidas más allá de cada umbral), media y desviación estándar. Las visualizaciones superponen la densidad de pérdidas baseline contra el escenario estresado lado a lado, con una curva de excedencia mostrando la cola acumulada y una tabla de impacto cuantificando el cambio en cada medida de riesgo. El TVaR es lo que más importa aquí para cumplimiento regulatorio. La CNSF lo requiere para cálculos de Requerimiento de Capital de Solvencia (RCS), así que este dashboard lo usa explícitamente, no VaR, como medida de riesgo primaria.
Detección de fraude
El fraude se detecta a través de dos canales paralelos que desembocan en un único score. El primero es estadístico: distancia de Mahalanobis. Para cada tipo de siniestro por separado, el modelo observa tres variables clave: el monto del siniestro, cuánto tiempo esperó el asegurado antes de reportarlo (en días) y el deducible. Calcula la distancia multivariada de cada siniestro a la región “normal” definida por la muestra completa. Esa distancia se convierte a percentil para interpretación más fácil (0 = típico, 100 = extremo). Una matriz de covarianza regularizada previene que las matemáticas exploten en casos singulares.
El segundo canal es basado en reglas. Cinco heurísticas detectan banderas estructurales de alerta: múltiples siniestros en la misma póliza en 60 días, un siniestro reportado en los primeros 30 días de la póliza, un monto superior a tres veces la mediana para ese tipo de siniestro, un retraso de reporte mayor a 10 días, o un monto superior al 90% de la suma asegurada. Cada regla vota independientemente.
El score compuesto final pondera 40% al estadístico de Mahalanobis y 60% a las banderas heurísticas. Un umbral de 0.7 identifica los siniestros más probables de ameritar investigación.
Decisiones de ingeniería
La aplicación contiene 17 módulos R organizados en tres capas. La capa inferior alberga 4 módulos de utilidades (métricas, tema, datos, exportación) que hacen todo el levantamiento matemático pesado. La capa superior contiene 13 módulos de interfaz, uno por cada pestaña del dashboard. Esta separación es intencional y rigurosa: el código actuarial no tiene cero dependencias de Shiny. Puedes probar el motor de tarificación o las funciones de reservas de forma aislada, en una sesión de R simple, sin necesidad de un servidor web.
La UI se construye encima con bslib y Bootstrap 5 para layout responsivo. Plotly maneja interactividad en gráficos, DT maneja filtrado y ordenamiento de tablas. Ambas librerías se integran limpiamente en Shiny y producen salida que el navegador entiende nativamente.
El deployment sigue el mismo patrón que el simulador de pensiones y SIMA: contenedor Docker en Google Cloud Run, con GitHub Actions impulsando CI/CD y Workload Identity Federation manejando autenticación.
Lo que aprendí
La variable que más afecta la tarificación en autos mexicanos es la zona geográfica, superando con creces la edad del conductor o el tipo de vehículo. CDMX y Estado de México acumulan la mayor frecuencia y severidad por lejos. Esto se alinea perfectamente con estadísticas de robo de AMIS; el robo se concentra en esos dos estados, y los GLMs capturan esa señal claramente.
La diferencia práctica entre Chain Ladder y Bornhuetter-Ferguson emerge en años de accidente inmaduros. Chain Ladder cabalga la volatilidad de los primeros link ratios hacia arriba y hacia abajo; Bornhuetter-Ferguson se ancla a la expectativa a priori del loss ratio y suaviza el ruido. Para autos con su cola de desarrollo de cuatro años, la divergencia es modesta. En responsabilidad civil de cola larga, la diferencia sería dramática.
Una limitación crítica: los datos son completamente sintéticos. Las correlaciones entre variables—por ejemplo, entre zona geográfica y tipo de vehículo—son por diseño, no descubiertas. Un conjunto de datos real de AMIS o CONDUSEF revelaría patrones e interacciones que no existen en datos generados. El siguiente paso sería obtener datasets públicos de CONDUSEF o negociar un acuerdo de compartir datos con una aseguradora real para reentrenar los GLMs en la realidad del mercado.
La aplicación está desplegada en Google Cloud Run y el código fuente está en GitHub.