Portafolio de Analista de Datos: 7 Proyectos End-to-End
De la pregunta de negocio al insight accionable. 7 proyectos de análisis de datos que cubren e-commerce, seguros, finanzas, pruebas A/B, KPIs ejecutivos y eficiencia operacional. SQL, Python, Streamlit, Next.js y Power BI.
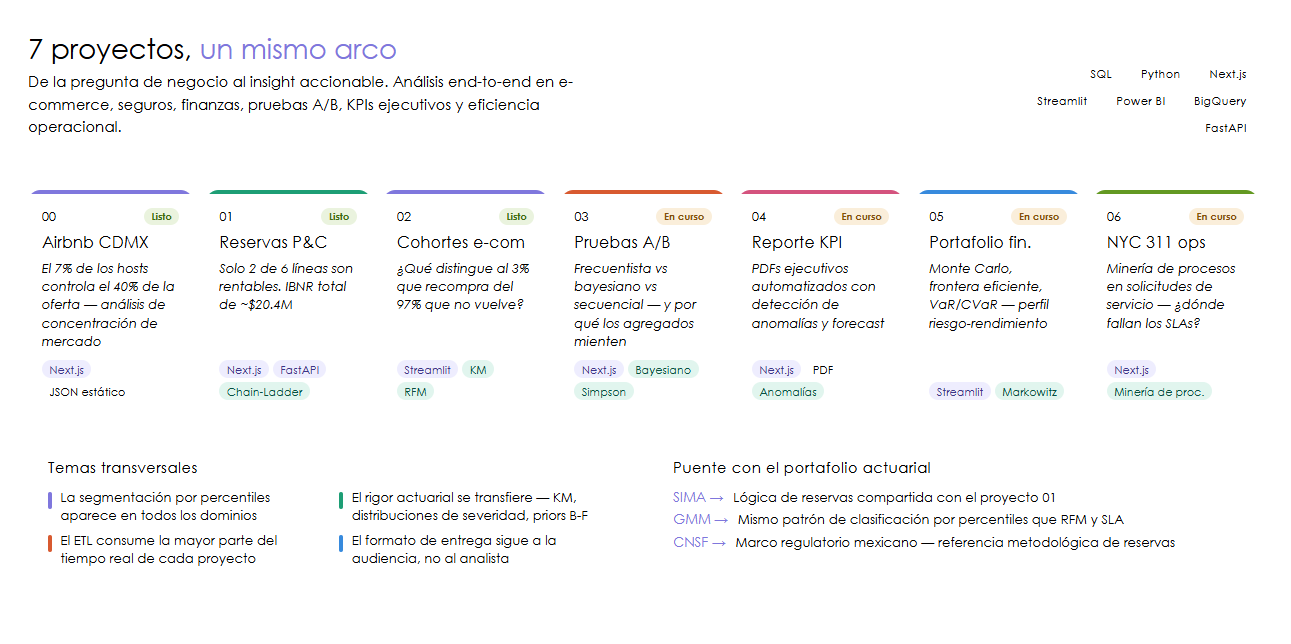
El trabajo de un analista de datos no es producir gráficas. Es convertir una pregunta de negocio en una decisión informada. Cada proyecto de este portafolio sigue ese arco completo: un stakeholder tiene una pregunta, los datos existen en algún formato inconveniente, el análisis produce un hallazgo, y el hallazgo se entrega en un formato que la audiencia puede usar para actuar.
Estos 7 proyectos cubren el arco completo del análisis de datos: desde la pregunta de negocio hasta el insight accionable, aplicado a dominios que van desde e-commerce hasta seguros. La formación actuarial aporta rigor estadístico (Kaplan-Meier, distribuciones de severidad, métodos de reserva) y los roles de DA exigen herramientas complementarias: SQL fluido, dashboards interactivos, storytelling para audiencias no técnicas, y la capacidad de moverse entre dominios sin perder profundidad.
El hilo conductor es metodológico: ETL cuidadoso, análisis exploratorio antes de cualquier conclusión, segmentación como herramienta recurrente, y entrega en el formato que el stakeholder necesita, ya sea un dashboard interactivo, un PDF automatizado o una app de Streamlit.
Los 7 proyectos
00 - Airbnb CDMX: análisis de mercado
Pregunta de negocio: ¿Cómo está estructurado el mercado de rentas cortas en Ciudad de México, y qué tan concentrada está la oferta?
El dataset de Inside Airbnb para CDMX contiene 27,051 listings con 79 columnas. El pipeline ETL limpia precios (llegan como strings con símbolo de moneda), gestiona nulos y segmenta hosts entre operadores enterprise y casuales. El hallazgo central: el 7% de los hosts controla el 40% de la oferta. Blueground, Mr. W y Clau no son anfitriones compartiendo su departamento, son empresas de hospitalidad operando a escala industrial. Cuauhtémoc concentra el 46% de los listings, mientras que las alcaldías periféricas como Tlalpan (MXN 2,493 promedio) muestran pricing premium con oferta escasa.
Dashboard construido con Next.js y Recharts, arquitectura estática (JSON precalculado, zero backend).
Estado: Completo | App en vivo | GitHub
01 - Reservas actuariales P&C: IBNR y siniestralidad
Pregunta de negocio: De las 6 líneas de negocio del portafolio, ¿cuáles son rentables y cuál es el IBNR (incurred but not reported, siniestros ocurridos pero no reportados) total que la aseguradora debe reservar?
Las aseguradoras en EE.UU. están obligadas a reportar su historial de siniestros al regulador en un formato estandarizado llamado NAIC Schedule P: básicamente una tabla que muestra, para cada año, cuánto se ha pagado en siniestros y cuánto falta por pagar. El problema es que muchos siniestros tardan años en reportarse. Un seguro de responsabilidad médica (Medical Malpractice, que cubre errores médicos como una cirugía fallida o un diagnóstico incorrecto) puede tener demandas que emergen 5 o 7 años después del evento. Muy diferente al seguro de auto, donde sabes el daño el mismo día del accidente.
Los métodos Chain-Ladder y Bornhuetter-Ferguson atacan ese problema de formas distintas: el primero extrapola los patrones históricos de desarrollo de siniestros para proyectar lo que falta; el segundo combina esa proyección con un supuesto externo del sector cuando los datos propios son escasos. Ambos producen una estimación del IBNR: el dinero que la aseguradora debe reservar hoy para siniestros que ya ocurrieron pero todavía no llegaron a la mesa.
El hallazgo más revelador: Medical Malpractice muestra un ratio de pérdidas de ~280%, lo que significa que por cada $100 de prima cobrada, la aseguradora pagó $280 en siniestros. No es una mala racha, es un problema estructural de tarificación. Solo Private Passenger Auto y Product Liability son rentables. El IBNR total del portafolio es ~$20.4M, concentrado en las líneas donde los siniestros toman más tiempo en resolverse.
Dashboard interactivo con Next.js y FastAPI: triángulos de pérdida en heatmap, waterfall de IBNR, frecuencia-severidad y tendencia de ratios combinados.
Estado: Completo | App en vivo | GitHub
02 - Cohortes de E-Commerce: retención, RFM y LTV
Pregunta de negocio: ¿Qué diferencia al 3% de clientes que recompran en Olist del 97% que no regresa?
El dataset de Olist tiene ~99K órdenes en 9 archivos de datos. El hallazgo que reencuadra todo el análisis: solo ~3% de los clientes vuelven a comprar. En un negocio de e-commerce normal eso sería una alarma; aquí es la realidad del mercado brasileño en ese período, y cambia la pregunta de “¿qué tan bien retenemos?” a “¿qué tiene de diferente ese 3%?”.
Un detalle técnico que importa: el dataset tiene dos identificadores de cliente, y usar el equivocado hace que cada orden parezca un cliente nuevo, inflando artificialmente la retención. Eso cambia los resultados completos, así que el primer paso es asegurarse de contar personas, no transacciones.
El análisis construye cuatro vistas sobre ese 3%: un mapa de calor que muestra cuántos clientes de cada mes de compra regresaron en los meses siguientes; una curva de supervivencia que traza a qué velocidad se van perdiendo los compradores con el tiempo; una segmentación RFM (Recencia, Frecuencia, Monto) que agrupa a los clientes por qué tan recientemente compraron, con qué frecuencia y cuánto gastaron; y una estimación del valor total que cada segmento generará durante su vida como cliente.
App de Streamlit desplegada en Cloud Run con pipeline técnico completo visible (notebooks convertidos a HTML embebidos en la app).
Estado: Completo | App en vivo | GitHub
03 - Pruebas A/B: frecuentista, bayesiano y paradoja de Simpson
Pregunta de negocio: Si ejecutamos un test A/B de conversión, ¿qué enfoque estadístico nos da la respuesta más confiable y por qué los resultados agregados pueden mentir?
Imagina que el equipo de producto quiere saber si cambiar el botón de checkout de azul a verde aumenta las conversiones. Corren el experimento dos semanas y el resultado global dice que la versión verde gana por 2 puntos porcentuales. ¿La lanzamos? Depende de cómo respondas tres preguntas: ¿es esa diferencia real o es ruido estadístico? ¿Cuánta confianza necesitas antes de tomar la decisión? Y si separas el resultado por usuarios móviles contra escritorio, ¿el verde sigue ganando en ambos grupos?
El proyecto evalúa esa misma situación con tres enfoques estadísticos: el test frecuentista clásico (¿el p-value está por debajo de 0.05?), inferencia bayesiana con PyMC (¿cuál es la probabilidad de que B sea mejor que A, y por cuánto?) y monitoreo secuencial (¿podemos parar antes si ya es obvio?). El análisis central es la paradoja de Simpson: cómo un resultado que parece claro a nivel global puede invertirse por completo al segmentar por subgrupo, un riesgo real en cualquier experimento de producto.
Dashboard interactivo con Next.js que permite explorar cada enfoque estadístico, calcular potencia de prueba y visualizar la convergencia bayesiana.
Estado: Completo | App en vivo | GitHub
04 - Reporte KPI Ejecutivo: métricas SaaS automatizadas
Pregunta de negocio: ¿Cómo automatizar la generación de reportes ejecutivos mensuales con detección de anomalías y forecast de métricas clave?
Los CEOs y directores no viven en dashboards. Reciben un PDF o una presentación una vez al mes. El problema con el proceso manual: tarda un día completo armarlo, los números siempre tienen algo de retraso, y las anomalías solo se detectan si alguien las nota. Un mes con churn inusualmente alto puede pasar desapercibido si nadie está mirando la gráfica correcta en el momento correcto.
Este pipeline reemplaza ese proceso. Un solo comando genera el reporte completo: calcula las métricas SaaS clave (MRR, churn, costo de adquisición, valor de vida del cliente), detecta automáticamente cualquier métrica que se desvíe de su tendencia histórica, proyecta el trimestre siguiente y produce un PDF bilingüe listo para enviar. El analista pasa su tiempo interpretando los hallazgos, no copiando números entre hojas de cálculo.
9 notebooks que cubren generación de datos, análisis exploratorio, detección de anomalías, forecasting, automatización de reportes, arquitectura backend, cálculos KPI, algoritmos de analítica y pipeline PDF. Dashboard Next.js complementario.
Estado: Completo | App en vivo | GitHub
05 - Portafolio Financiero: Monte Carlo y frontera eficiente
Pregunta de negocio: Dado un portafolio diversificado de ETFs, ¿realmente vale la pena esa diversificación comparada con simplemente comprar el S&P 500?
El dashboard analiza un portafolio real de 6 ETFs que cubren distintas clases de activos, con datos en vivo de Yahoo Finance y el S&P 500 como benchmark. La pregunta central es simple pero incómoda: si tu portafolio diversificado tuvo peor rendimiento ajustado por riesgo que un solo ETF del índice, la diversificación te costó dinero en lugar de protegerte.
Para responder eso con rigor, el análisis calcula la frontera eficiente de Markowitz (el conjunto de portafolios que maximizan rendimiento para cada nivel de riesgo), corre simulaciones Monte Carlo para ver el rango de escenarios futuros posibles, y mide el riesgo de distintas formas: el VaR (pérdida máxima esperada en condiciones normales), el CVaR (pérdida esperada en los peores escenarios) y los ratios Sharpe y Sortino (rendimiento por unidad de riesgo). El resultado es una respuesta cuantitativa a si tu mezcla de activos tiene sentido matemático.
5 notebooks cubriendo adquisición de datos, construcción de portafolio, análisis de rendimiento, analítica de riesgo y optimización de frontera Monte Carlo.
Estado: Completo | App en vivo | GitHub
06 - Eficiencia Operacional: NYC 311, minería de procesos y SLA
Pregunta de negocio: ¿Qué patrones de ineficiencia existen en las solicitudes de servicio de NYC 311 y dónde se violan los SLAs sistemáticamente?
NYC 311 es el sistema de quejas de servicio público de Nueva York: los residentes reportan baches, ruido, plagas de ratas, violaciones de construcción, calefacción rota, basura acumulada. Más de 30 millones de registros desde 2010, repartidos entre más de 40 tipos de queja y más de 20 agencias distintas. Es un dataset enorme, pero lo que lo hace interesante para análisis operacional no es el volumen, es lo que captura de forma implícita.
Los datos registran cuándo se abrió cada queja y cuándo se cerró, pero no los pasos intermedios. La minería de procesos reconstruye esos flujos ocultos: si una queja de edificio en mal estado tarda 14 días en promedio pero las más rápidas se cierran en 2, el algoritmo busca qué tienen en común las que se resuelven rápido. Eso revela los cuellos de botella reales, no los reportados.
Lo que el análisis permite ver que los números simples no muestran: algunas agencias tienen compromisos de tiempo de respuesta (SLA, service level agreement) imposibles de cumplir dado su volumen de quejas, no porque sean lentas sino porque el compromiso se fijó sin considerar la demanda real. Los tiempos de respuesta en ciertos barrios son sistemáticamente más lentos para quejas idénticas a las de otras zonas. Ciertos tipos de queja tienen picos estacionales predecibles que se acumulan en rezagos si las agencias no ajustan capacidad. El dashboard hace navegables esos patrones por agencia, tipo de queja, barrio y período.
Dashboard Next.js con visualizaciones de flujos de proceso, heatmaps de SLA y rankings de agencias.
Estado: Completo | App en vivo | GitHub
Decisiones de arquitectura
La elección de herramienta de entrega no es arbitraria. Depende de tres factores: quién es la audiencia, qué tan interactivo necesita ser el output, y cuál es el ciclo de actualización.
Next.js (proyectos 00, 01, 03, 04, 06) cuando el dashboard es un producto terminado que necesita control total sobre la estética, modo oscuro, responsive en móvil, y componentes reutilizables entre proyectos. El costo es mayor: requiere conocimiento de React, TypeScript y un pipeline de build. Se justifica cuando el dashboard tiene vida larga o cuando los componentes se reutilizan (KPICard, ChartContainer y ThemeToggle se comparten entre todos los dashboards de Next.js).
Streamlit (proyectos 02, 05) cuando el análisis vive en Python y la prioridad es pasar de notebook a app interactiva con mínimo overhead. Streamlit es la opción correcta cuando el analista es la misma persona que va a mantener la app y el stack de Python ya está establecido. El patrón de notebook-en-Streamlit (convertir notebooks a HTML y embederlos como página de proceso técnico) añade valor de portafolio: el viewer ve el código completo detrás de cada visualización sin salir de la app.
Power BI aparece en el plan para los proyectos 04 y 06 como formato complementario, orientado a stakeholders que ya trabajan en el ecosistema Microsoft y esperan filtros de segmentación drag-and-drop.
La decisión entre JSON estático (Airbnb, zero backend) y API con FastAPI (Olist, Insurance) depende de si los filtros del usuario cambian el cómputo subyacente. Si los datos caben en memoria y las agregaciones son fijas, JSON estático elimina toda la complejidad de infraestructura. Si el análisis de cohortes o los triángulos de pérdida dependen de los filtros aplicados, el backend es necesario.
Aprendizajes transversales
Después de construir 7 proyectos en dominios diferentes, los patrones recurrentes son más instructivos que cualquier hallazgo individual.
El ETL consume la mayor parte del tiempo real. En todos los proyectos, la limpieza y transformación de datos tomó más tiempo que el análisis. Los precios de Airbnb llegan como strings con símbolo de moneda y comas. Los timestamps de Olist necesitan parsing cuidadoso para construir cohortes correctas. Los datos del NAIC Schedule P requieren validación cruzada entre tablas antes de construir triángulos confiables. Los datos de NYC 311 tienen inconsistencias entre agencias en cómo registran los tipos de solicitud. La metodología es transferible: validación de tipos, manejo explícito de nulos, logging de registros descartados.
La segmentación por percentiles aparece en todos los dominios. Clasificar hosts de Airbnb en enterprise vs casual (por número de listings), segmentar clientes de Olist en clusters RFM (por recencia, frecuencia y monto), clasificar líneas de negocio de seguros por perfil de cola, segmentar agencias de NYC por cumplimiento de SLA. El patrón es idéntico: definir umbrales sobre una distribución, asignar etiquetas, medir diferencias entre grupos, tomar decisiones basadas en la heterogeneidad.
El 3% de recompra de Olist cambia cómo se enmarca un análisis de cohortes. Cuando la gran mayoría de clientes son one-time buyers, la pregunta no es “qué tan bien retenemos” sino “qué diferencia a los que regresan.” Ese reencuadre aplica en seguros (qué diferencia a las pólizas que renuevan), en SaaS (qué diferencia a los usuarios que no hacen churn) y en cualquier negocio con alta tasa de abandono.
El rigor estadístico de la formación actuarial se aplica directamente a producto. Kaplan-Meier es una curva que muestra qué fracción de clientes seguía activa en cada punto del tiempo, sin necesitar que todos hayan abandonado para estimar la tendencia: en seguros modela cuántos asegurados permanecen vivos; en producto, cuántos usuarios siguen comprando. Las distribuciones de severidad no describen solo el monto promedio de una transacción sino toda la forma de la distribución: cuántos clientes gastan $50, cuántos $500, cuántos $5,000, que es exactamente lo que se necesita para estimar el valor de vida de un cliente sin que los casos extremos distorsionen el promedio. Bornhuetter-Ferguson combina lo que tus datos actuales dicen con lo que la experiencia histórica del sector sugiere, útil cuando tienes pocos registros propios para confiar solo en ellos. El punto no es los nombres. Es que la analítica de seguros y la analítica de producto resuelven el mismo problema: estimar lo que aún no ha ocurrido a partir de lo que sí observaste.
Conexiones con el portafolio actuarial
Este portafolio de DA no existe en aislamiento. Los proyectos actuariales en el portafolio principal complementan directamente el trabajo aquí:
- SIMA (Sistema Integral de Modelación Actuarial) comparte con el proyecto 01 la lógica de cálculo de reservas, aunque para productos de vida en lugar de daños. Los mismos factores de descuento y patrones de desarrollo que aparecen en los triángulos del NAIC viven como funciones modulares en el motor de SIMA.
- GMM Explorer conecta con la segmentación de este portafolio: definir grupos a partir de distribuciones de siniestros de Gastos Médicos Mayores es el mismo patrón de clasificación por percentiles que aparece en RFM, segmentación de hosts y análisis de SLA.
- Las notas técnicas de seguros (vida y daños) son el referente regulatorio: los marcos de la CNSF que gobiernan cómo se calculan reservas en el mercado mexicano. La metodología del proyecto 01 es análoga, adaptada al contexto americano (NAIC).
Material de referencia
- Repositorio principal en GitHub: Código completo de los 7 proyectos, notebooks numerados, queries SQL, pipelines ETL y configuración de despliegue.
- Airbnb CDMX (App en vivo): Dashboard Next.js con análisis de mercado de rentas cortas.
- Reservas Actuariales P&C (App en vivo): Dashboard Next.js + FastAPI con triángulos de pérdida y IBNR.
- Cohortes E-Commerce (App en vivo): Streamlit desplegado en Cloud Run con pipeline técnico completo.
- Pruebas A/B (App en vivo): Dashboard Next.js con enfoques frecuentista, bayesiano y paradoja de Simpson.
- Reporte KPI Ejecutivo (App en vivo): Dashboard Next.js con métricas SaaS automatizadas.
- Portafolio Financiero (App en vivo): Dashboard Next.js + FastAPI con datos en vivo de yfinance.
- Eficiencia Operacional (App en vivo): Dashboard Next.js con minería de procesos y análisis de SLA.